How AI can spot inappropriate videos just by reading their captions
Ever wondered how platforms like YouTube and TikTok manage to filter out millions of inappropriate videos every day?
While most people think it’s all about analyzing the actual video frames.
There’s a surprisingly effective method that focuses on something much simpler: the captions.
The Smart Way
Instead of trying to analyze every pixel in a video (which is computationally expensive),
we can get remarkably good results by focusing on the text that accompanies videos.
This approach leverages the power of Natural Language Processing (NLP) and/or machine learning to identify problematic content.
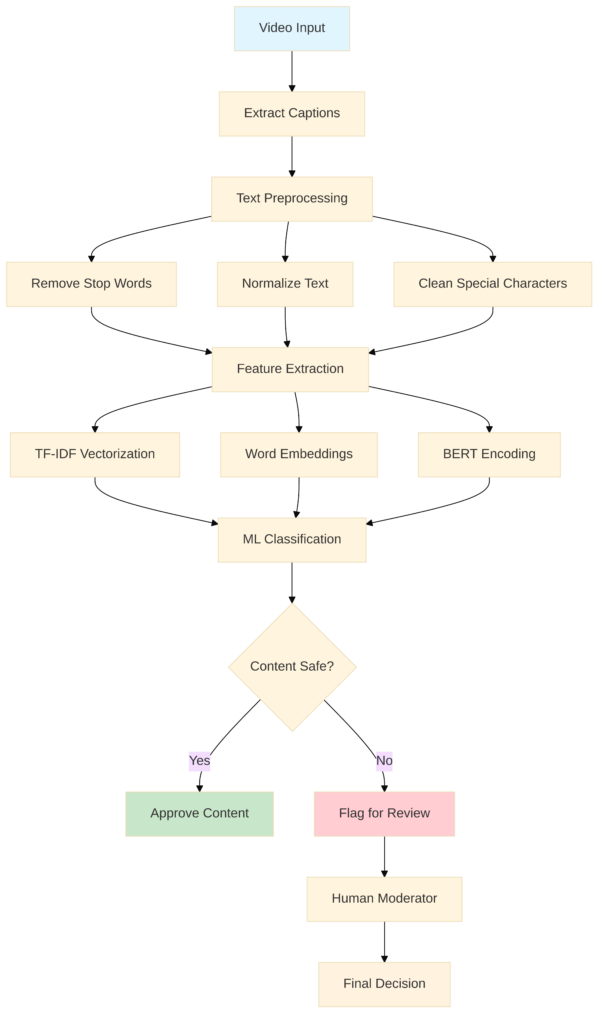
The process follows a systematic workflow:
- We start by extracting captions from videos
- Clean and preprocess the text
- Extract meaningful features
- Finally classify the content using trained machine learning models.
Implementation
Here’s a simplified pseudocode showing how the caption extraction and classification works:
# Caption-based Content Detection System
function detectInappropriateContent(video_file):
# Step 1: Extract captions
captions = extractCaptions(video_file)
# Step 2: Preprocess text
cleaned_text = preprocessText(captions)
# Step 3: Feature extraction
features = extractFeatures(cleaned_text)
# Step 4: Classification
prediction = classifyContent(features)
return prediction
function preprocessText(raw_text):
# Remove special characters and normalize
text = removeSpecialChars(raw_text)
text = toLowerCase(text)
text = removeStopWords(text)
text = stemWords(text)
return text
function extractFeatures(text):
# Multiple feature extraction methods
tfidf_features = calculateTFIDF(text)
word_embeddings = getWordEmbeddings(text)
bert_features = getBERTEncoding(text)
# Combine features
combined_features = concatenate(tfidf_features, word_embeddings, bert_features)
return combined_features
function classifyContent(features):
# Load pre-trained model
model = loadModel("content_classifier.pkl")
# Make prediction
probability = model.predict_proba(features)
if probability[inappropriate] > THRESHOLD:
return "INAPPROPRIATE"
else:
return "SAFE"ML Pipeline
The training process involves several sophisticated steps to ensure high accuracy:
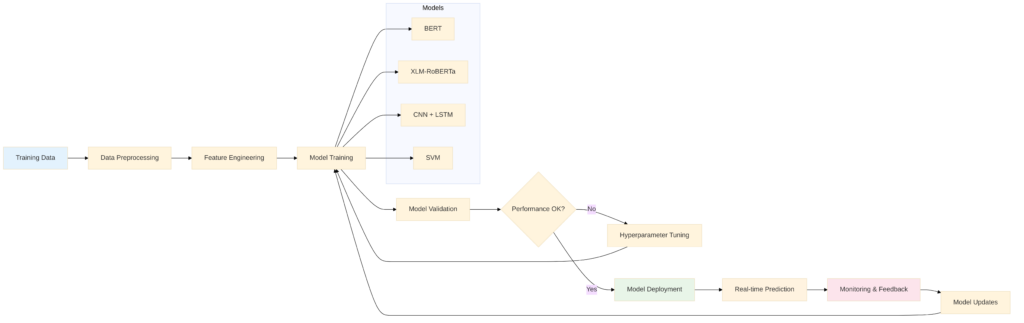
Here’s how we train the classification model:
# Training Pipeline Pseudocode
function trainContentClassifier():
# Load and prepare training data
training_data = loadLabeledDataset()
# Split data
train_set, validation_set, test_set = splitData(training_data)
# Preprocess all datasets
train_features = preprocessAndExtractFeatures(train_set)
val_features = preprocessAndExtractFeatures(validation_set)
# Train multiple models
models = []
models.append(trainBERT(train_features))
models.append(trainXLMRoBERTa(train_features))
models.append(trainCNNLSTM(train_features))
# Validate and select best model
best_model = None
best_accuracy = 0
for model in models:
accuracy = evaluate(model, val_features)
if accuracy > best_accuracy:
best_accuracy = accuracy
best_model = model
# Final evaluation
test_accuracy = evaluate(best_model, test_set)
return best_model, test_accuracyWhy This Approach Works So Well
- Speed and Efficiency: Processing text is much faster than analyzing video frames. You can scan thousands of captions in the time it takes to analyze a single video.
- Context Understanding: Advanced AI models don’t just look for banned words – they understand context. They can tell the difference between discussing a topic academically versus promoting harmful content.
- Multilingual Support: These systems can work across different languages, making them perfect for global platforms.
- Cost-Effective: Text analysis requires significantly less computational power than video analysis, making it scalable for platforms with millions of uploads daily.
Real-World Performance
Recent research shows impressive results with this approach.
Models like XLM-RoBERTa have achieved 96% accuracy in detecting toxic content,
while specialized systems for cursive text detection in videos have reached F-measures of 0.91 on datasets containing over 11,000 video frames.
Here’s a simple performance monitoring pseudocode:
# Performance Monitoring System
function monitorModelPerformance():
while system_running:
# Collect recent predictions
recent_predictions = getRecentPredictions(last_24_hours)
# Calculate metrics
accuracy = calculateAccuracy(recent_predictions)
precision = calculatePrecision(recent_predictions)
recall = calculateRecall(recent_predictions)
# Check for performance degradation
if accuracy < MINIMUM_THRESHOLD:
triggerModelRetraining()
sendAlert("Model performance below threshold")
# Log metrics
logMetrics(accuracy, precision, recall)
sleep(1_hour)The Bottom Line
Caption-based content detection represents a smart, efficient approach to content moderation.
By focusing on what people are saying rather than just what they’re showing,
platforms can create safer environments while keeping computational costs manageable.
As AI continues to improve, we can expect these systems to become even more accurate and nuanced in their understanding of context and intent.
The combination of advanced NLP techniques, robust machine learning pipelines,
and continuous monitoring creates a powerful system that can adapt to new types of inappropriate content as they emerge.
References
There are many inappropriate video contents that actually have no talking