

作为phper,一般接触算法的编程不多。 但基本的排序算法还是应该掌握。 毕竟算法作为程序的核心,算法的好坏决定了程序的质量。 本文将依次介绍一些常用的排序算法,以及PHP实现。
1 快速排序
快速排序是由东尼·霍尔发展的一种排序算法。 在平均状况下,排序 n 个项目要Ο(n log n)次比较。 在最坏状况下则需要Ο(n²)次比较,但这种状况并不常见。 事实上,快速排序通常明显比其他Ο(n log n) 算法更快,因为它的内部循环可以在大部分的架构上,很有效率地被实现出来。

快速排序采用分治法实现排序,具体步骤:
- 从数列中挑出一个数作为基准元素。通常选择第一个或最后一个元素。
- 扫描数列,以基准元素为比较对象,把数列分成两个区。规则是:小的移动到基准元素前面,大的移到后面,相等的前后都可以。分区完成之后,基准元素就处于数列的中间位置。
- 然后再用同样的方法,递归地排序划分的两部分。
递归的结束条件是数列的大小是0或1,也就是永远都已经被排序好了。 PHP代码实现:
function quickSort($arr)
{
$len = count($arr);
// 先设定结束条件,判断是否需要继续进行
if($len <= 1) {
return $arr;
}
// 选择第一个元素作为基准元素
$pivot = $arr[0];
// 初始化左数组
$left = $right = array();
// 初始化大于基准元素的右数组
$right = array();
// 遍历除基准元素外的所有元素,按照大小关系放入左右数组内
for ($i = 1; $i < $len ; $i++) {
if ($arr[$i] < $pivot) {
$left[] = $arr[$i];
} else {
$right[] = $arr[$i];
}
}
// 再分别对左右数组进行相同的排序
$left = quickSort($left);
$right = quickSort($right);
// 合并基准元素和左右数组
return array_merge($left, array($pivot), $right);
}原地排序版本,不需要额外的存储空间:
function partition(&$arr, $leftIndex, $rightIndex)
{
$pivot = $arr[($leftIndex + $rightIndex) / 2];
while ($leftIndex <= $rightIndex) {
while ($arr[$leftIndex] < $pivot) {
$leftIndex++;
}
while ($arr[$rightIndex] > $pivot) {
$rightIndex--;
}
if ($leftIndex <= $rightIndex) {
list($arr[$leftIndex], $arr[$rightIndex]) = [$arr[$rightIndex], $arr[$leftIndex]];
$leftIndex++;
$rightIndex--;
}
}
return $leftIndex;
}
function quickSort(&$arr, $leftIndex, $rightIndex)
{
if ($leftIndex < $rightIndex) {
$index = partition($arr, $leftIndex, $rightIndex);
quickSort($arr, $leftIndex, $index - 1);
quickSort($arr, $index, $rightIndex);
}
}2 冒泡排序
冒泡排序是一种简单的排序算法。 算法重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。 走访数列的工作重复地进行,直到没有再需要交换,也就是说该数列已经排序完成。
因为排序过程让较大的数往下沉,较小的往上冒,故而叫冒泡法。


算法步骤:
- 从第一个元素开始,比较相邻的元素,如果第一个比第二个大,就交换他们两个。
- 从开始第一对到结尾的最后一对,对每一对相邻元素作同样的工作。比较结束后,最后的元素应该会是最大的数。
- 对所有的元素重复以上的步骤,除了最后一个。
- 重复上面的步骤,每次比较的对数会越来越少,直到没有任何一对数字需要比较。
PHP代码实现:
function bubbleSort($arr)
{
$len = count($arr);
for($i = 1; $i < $len; $i++) {
for($k = 0; $k < $len - $i; $k++) {
if($arr[$k] > $arr[$k + 1]) {
$tmp = $arr[$k + 1];
$arr[$k + 1] = $arr[$k];
$arr[$k] = $tmp;
}
}
}
return $arr;
}3 插入排序
插入排序是一种简单直观的排序算法。
插入排序的工作原理是:**将需要排序的数,与前面已经排好序的数据从后往前进行比较,使其插入到相应的位置。
**插入排序在实现上,通常采用in-place排序,即只需用到O(1)的额外空间的排序。
因而,在从后向前扫描过程中,需要反复把已排序元素逐步向后挪位,为最新元素提供插入空间。
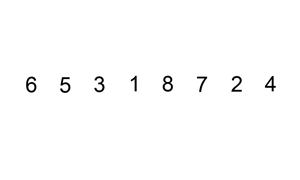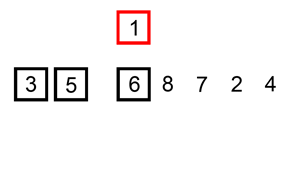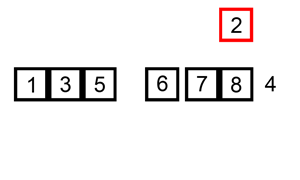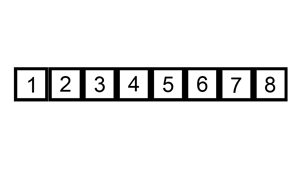

算法步骤:
- 从第一个元素开始,该元素可以认为已经被排序;
- 取出下一个元素,在已经排序的元素序列中从后向前扫描;
- 如果以排序的元素大于新元素,将该元素移到下一位置;
- 重复步骤3,直到找到已排序的元素小于或者等于新元素的位置;
- 将新元素插入到该位置中;
- 重复步骤2。
PHP代码实现:
function insertSort($arr)
{
$len = count($arr);
for ($i = 1; $i < $len; $i++) {
$tmp = $arr[$i];
for ($j = $i - 1; $j >= 0; $j--) {
if ($tmp < $arr[$j]) {
$arr[$j + 1] = $arr[$j];
$arr[$j] = $tmp;
} else {
break;
}
}
}
return $arr;
}4 选择排序
选择排序是一种简单直观的排序算法。


算法步骤:
- 首先,在序列中找到最小元素,存放到排序序列的起始位置;
- 接着,从剩余未排序元素中继续寻找最小元素,放到已排序序列的末尾。
- 重复第二步,直到所有元素均排序完毕。
PHP代码实现:
function selectSort($arr)
{
$len = count($arr);
for ($i = 0; $i < $len; $i++) {
$p = $i;
for ($j = $i + 1; $j < $len; $j++) {
if ($arr[$p] > $arr[$j]) {
$p = $j;
}
}
$tmp = $arr[$p];
$arr[$p] = $arr[$i];
$arr[$i] = $tmp;
}
return $arr;
}5 归并排序
归并排序是建立在归并操作上的一种有效的排序算法。
归并排序将待排序的序列分成若干组,保证每组都有序,然后再进行合并排序,最终使整个序列有序。
该算法是采用分治法的一个非常典型的应用。
算法步骤:
- 申请空间,使其大小为两个已经排序序列之和,该空间用来存放合并后的序列;
- 设定两个指针,最初位置分别为两个已经排序序列的起始位置
- 比较两个指针所指向的元素,选择相对小的元素放入到合并空间,并移动指针到下一位置
- 重复步骤3直到某一指针达到序列尾
- 将另一序列剩下的所有元素直接复制到合并序列尾
排序效果:

PHP实现代码:
/**
* 归并排序
*
* @param array $lists
* @return array
*/
function merge_sort(array $lists)
{
$n = count($lists);
if ($n <= 1) {
return $lists;
}
$left = merge_sort(array_slice($lists, 0, floor($n / 2)));
$right = merge_sort(array_slice($lists, floor($n / 2)));
$lists = merge($left, $right);
return $lists;
}
function merge(array $left, array $right)
{
$lists = [];
$i = $j = 0;
while ($i < count($left) && $j < count($right)) {
if ($left[$i] < $right[$j]) {
$lists[] = $left[$i];
$i++;
} else {
$lists[] = $right[$j];
$j++;
}
}
$lists = array_merge($lists, array_slice($left, $i));
$lists = array_merge($lists, array_slice($right, $j));
return $lists;
}6 堆排序
堆排序是指利用堆这种数据结构所设计的一种排序算法。
堆积是一个近似完全二叉树的结构,并同时满足堆积的性质:即子结点的键值或索引总是小于(或者大于)它的父节点。 堆排序的平均时间复杂度为Ο(nlogn) 。
算法步骤:
- 创建一个堆
H[0..n-1]; - 把堆首(最大值)和堆尾互换;
- 把堆的尺寸缩小
1,并调用shift_down(0),目的是把新的数组顶端数据调整到相应位置; - 重复步骤
2,直到堆的尺寸为1。
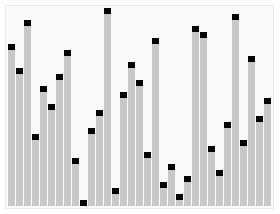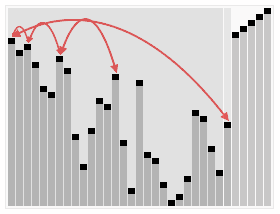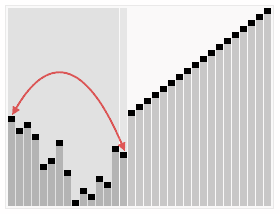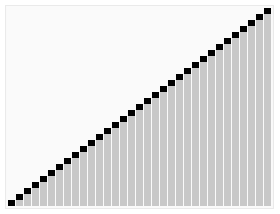
PHP实现代码:
/**
* 堆排序
*
* @param array $lists
* @return array
*/
function heap_sort(array $lists)
{
$n = count($lists);
build_heap($lists);
while (--$n) {
$val = $lists[0];
$lists[0] = $lists[$n];
$lists[$n] = $val;
heap_adjust($lists, 0, $n);
//echo sort: . $n . \t . implode(', ', $lists) . PHP_EOL;
}
return $lists;
}
function build_heap(array &$lists)
{
$n = count($lists) - 1;
for ($i = floor(($n - 1) / 2); $i >= 0; $i--) {
heap_adjust($lists, $i, $n + 1);
//echo build: . $i . \t . implode(', ', $lists) . PHP_EOL;
}
//echo build ok: . implode(', ', $lists) . PHP_EOL;
}
function heap_adjust(array &$lists, $i, $num)
{
if ($i > $num / 2) {
return;
}
$key = $i;
$leftChild = $i * 2 + 1;
$rightChild = $i * 2 + 2;
if ($leftChild < $num && $lists[$leftChild] > $lists[$key]) {
$key = $leftChild;
}
if ($rightChild < $num && $lists[$rightChild] > $lists[$key]) {
$key = $rightChild;
}
if ($key != $i) {
$val = $lists[$i];
$lists[$i] = $lists[$key];
$lists[$key] = $val;
heap_adjust($lists, $key, $num);
}
}7 希尔排序
希尔排序,也称递减增量排序算法,是插入排序的一种更高效的改进版本。
但希尔排序是非稳定排序算法。 希尔排序是基于插入排序的以下两点性质而提出改进方法的:
- 插入排序在对几乎已经排好序的数据操作时, 效率高, 即可以达到线性排序的效率
- 但插入排序一般来说是低效的, 因为插入排序每次只能将数据移动一位

算法步骤:
- 先将整个待排序的记录序列分割成为若干子序列,分别进行直接插入排序
- 待整个序列中的记录“基本有序”时,再对全体记录进行依次直接插入排序。
PHP实现代码:
/**
* 希尔排序 标准
*
* @param array $lists
* @return array
*/
function shell_sort(array $lists)
{
$n = count($lists);
$step = 2;
$gap = intval($n / $step);
while ($gap > 0) {
for ($gi = 0; $gi < $gap; $gi++) {
for ($i = $gi; $i < $n; $i += $gap) {
$key = $lists[$i];
for ($j = $i - $gap; $j >= 0 && $lists[$j] > $key; $j -= $gap) {
$lists[$j + $gap] = $lists[$j];
$lists[$j] = $key;
}
}
}
$gap = intval($gap / $step);
}
return $lists;
}8 基数排序
基数排序是一种非比较型整数排序算法,其原理是将整数按位数切割成不同的数字,然后按每个位数分别比较。
由于整数也可以表达字符串(比如名字或日期)和特定格式的浮点数,所以基数排序也不是只能使用于整数。


说基数排序之前,我们简单介绍桶排序: 桶排序是将阵列分到有限数量的桶子里。 每个桶子再个别排序,有可能再使用别的排序算法,或是以递回方式继续使用桶排序进行排序。 桶排序是鸽巢排序的一种归纳结果。 当要被排序的阵列内的数值是均匀分配的时候,桶排序使用线性时间O(n)。 但桶排序并不是 比较排序,他不受到 O(n log n) 下限的影响。 简单来说,就是把数据分组,放在一个个的桶中,然后对每个桶里面的在进行排序。
例如,要对大小为[1..1000]范围内的n个整数A[1..n]排序 首先,可以把桶设为大小为10的范围,具体而言,设集合B[1]存储[1..10]的整数,集合B[2]存储 (10..20]的整数,……集合B[i]存储( (i-1)10, i10]的整数,i = 1,2,..100。总共有 100个桶。
然后,对A[1..n]从头到尾扫描一遍,把每个A[i]放入对应的桶B[j]中。 再对这100个桶中每个桶里的数字排序,这时可用冒泡,选择,乃至快排,一般来说任 何排序法都可以。
最后,依次输出每个桶里面的数字,且每个桶中的数字从小到大输出,这 样就得到所有数字排好序的一个序列了。 假设有n个数字,有m个桶,如果数字是平均分布的,则每个桶里面平均有n/m个数字。 如果对每个桶中的数字采用快速排序,那么整个算法的复杂度是 O(n + m n/mlog(n/m)) = O(n + nlogn – nlogm) 从上式看出,当m接近n的时候,桶排序复杂度接近O(n) 当然,以上复杂度的计算是基于输入的n个数字是平均分布这个假设的。这个假设是很强的 ,实际应用中效果并没有这么好。如果所有的数字都落在同一个桶中,那就退化成一般的排序了。
前面说的几大排序算法 ,大部分时间复杂度都是O(n²),也有部分排序算法时间复杂度是O(nlogn)。而桶式排序却能实现O(n)的时间复杂度。
但桶排序的缺点是:
1)首先是空间复杂度比较高,需要的额外开销大。排序有两个数组的空间开销,一个存放待排序数组,一个就是所谓的桶,比如待排序值是从0到m-1,那就需要m个桶,这个桶数组就要至少m个空间。
2)其次待排序的元素都要在一定的范围内等等。
/**
* 基数排序
*
* @param array $lists
* @return array
*/
function radix_sort(array $lists)
{
$radix = 10;
$max = max($lists);
$k = ceil(log($max, $radix));
if ($max == pow($radix, $k)) {
$k++;
}
for ($i = 1; $i <= $k; $i++) {
$newLists = array_fill(0, $radix, []);
for ($j = 0; $j < count($lists); $j++) {
$key = $lists[$j] / pow($radix, $i - 1) % $radix;
$newLists[$key][] = $lists[$j];
}
$lists = [];
for ($j = 0; $j < $radix; $j++) {
$lists = array_merge($lists, $newLists[$j]);
}
}
return $lists;
}9 总结
各种排序的稳定性,时间复杂度、空间复杂度、稳定性总结如下图:
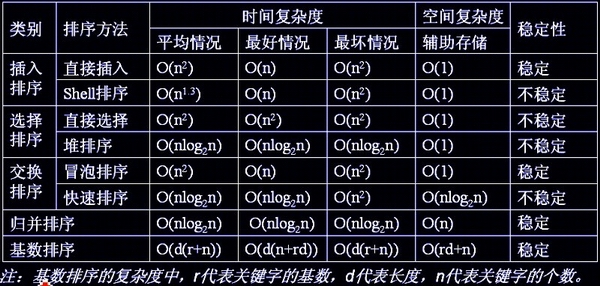

关于时间复杂度:
- 平方阶(O(n2))排序各类简单排序:直接插入、直接选择和冒泡排序;
- 线性对数阶(O(nlog2n))排序 快速排序、堆排序和归并排序;
- O(n1+§))排序,§是介于0和1之间的常数。希尔排序
- 线性阶(O(n))排序基数排序,此外还有桶、箱排序。
关于稳定性:
- 稳定的排序算法:冒泡排序、插入排序、归并排序和基数排序
- 不是稳定的排序算法:选择排序、快速排序、希尔排序、堆排序
参考地址: